
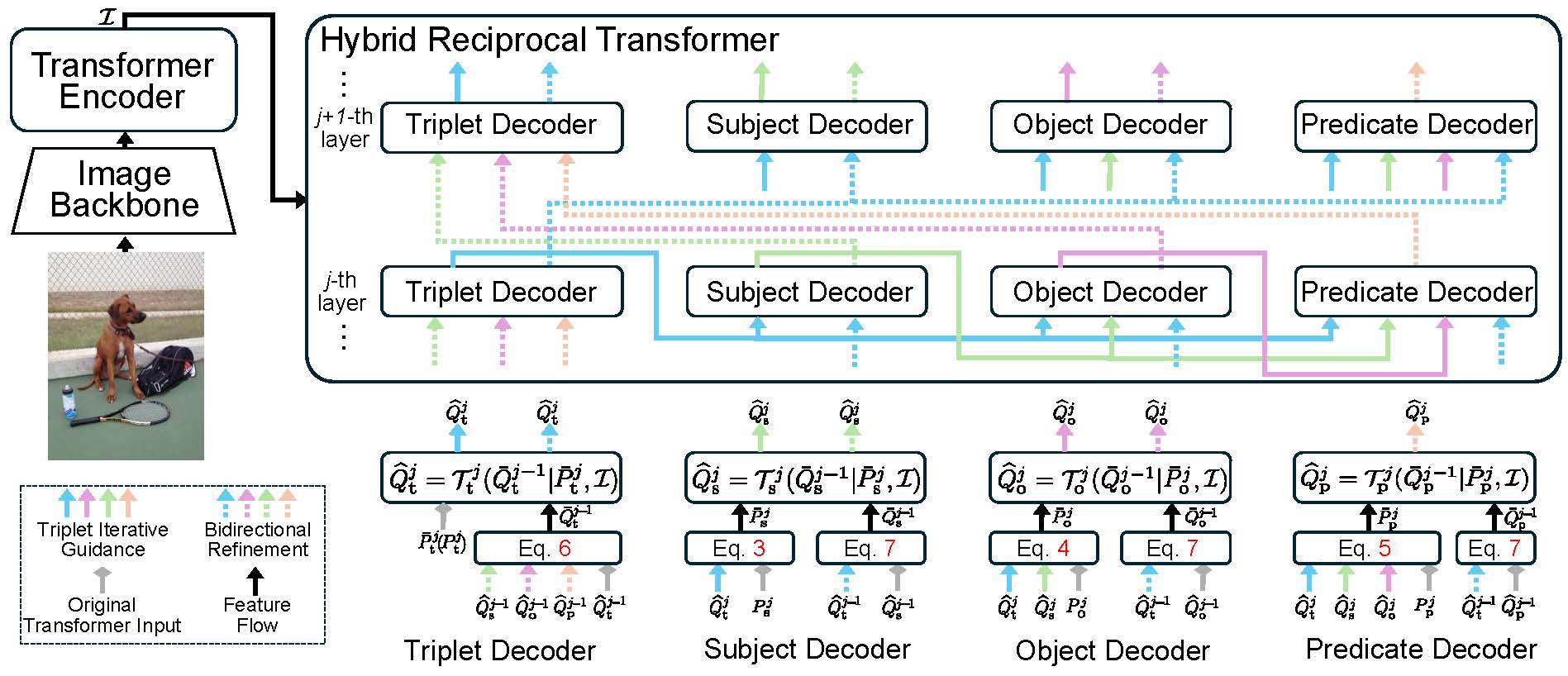
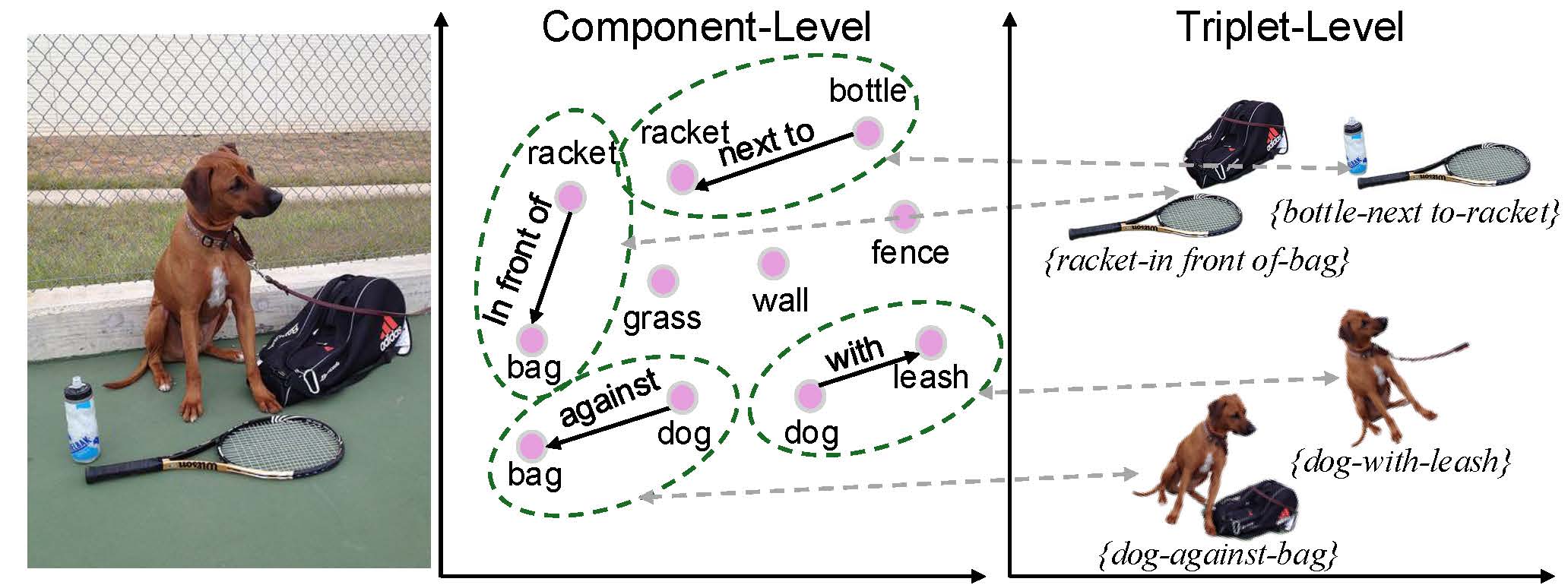
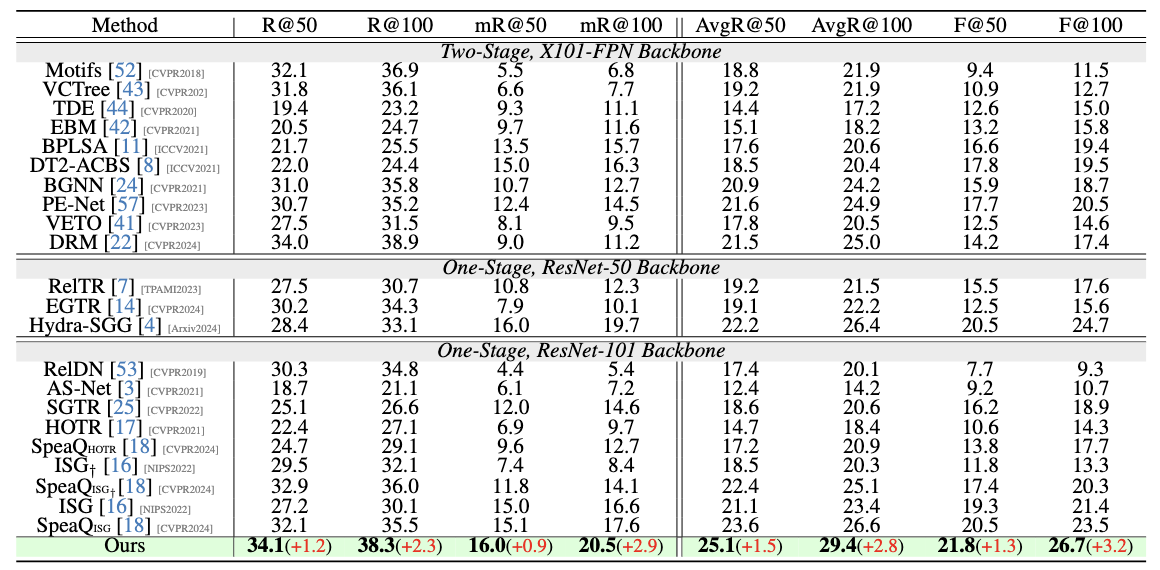
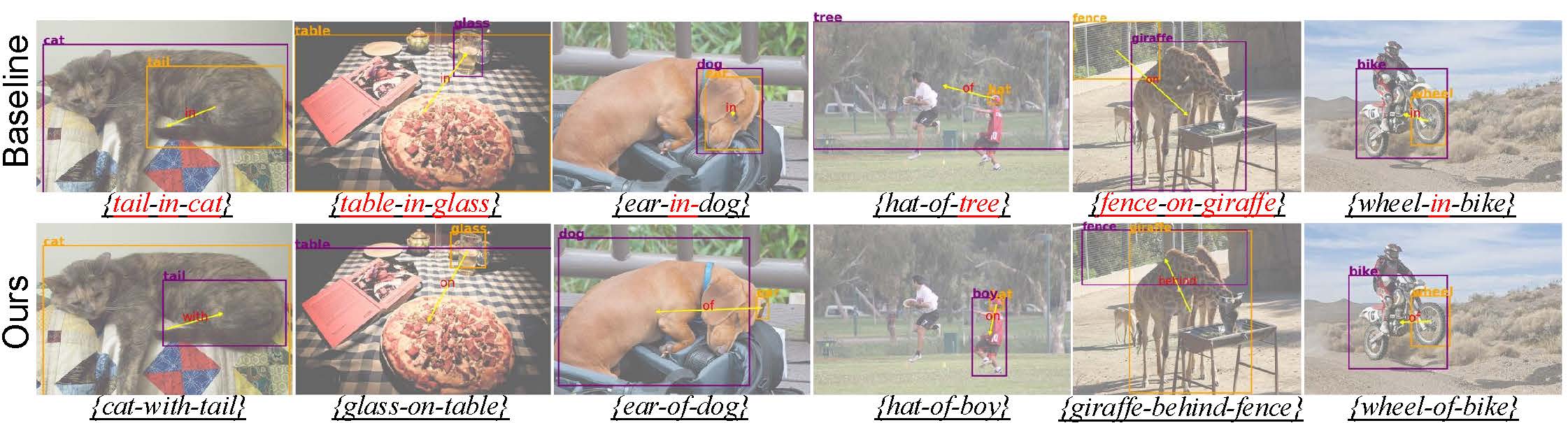
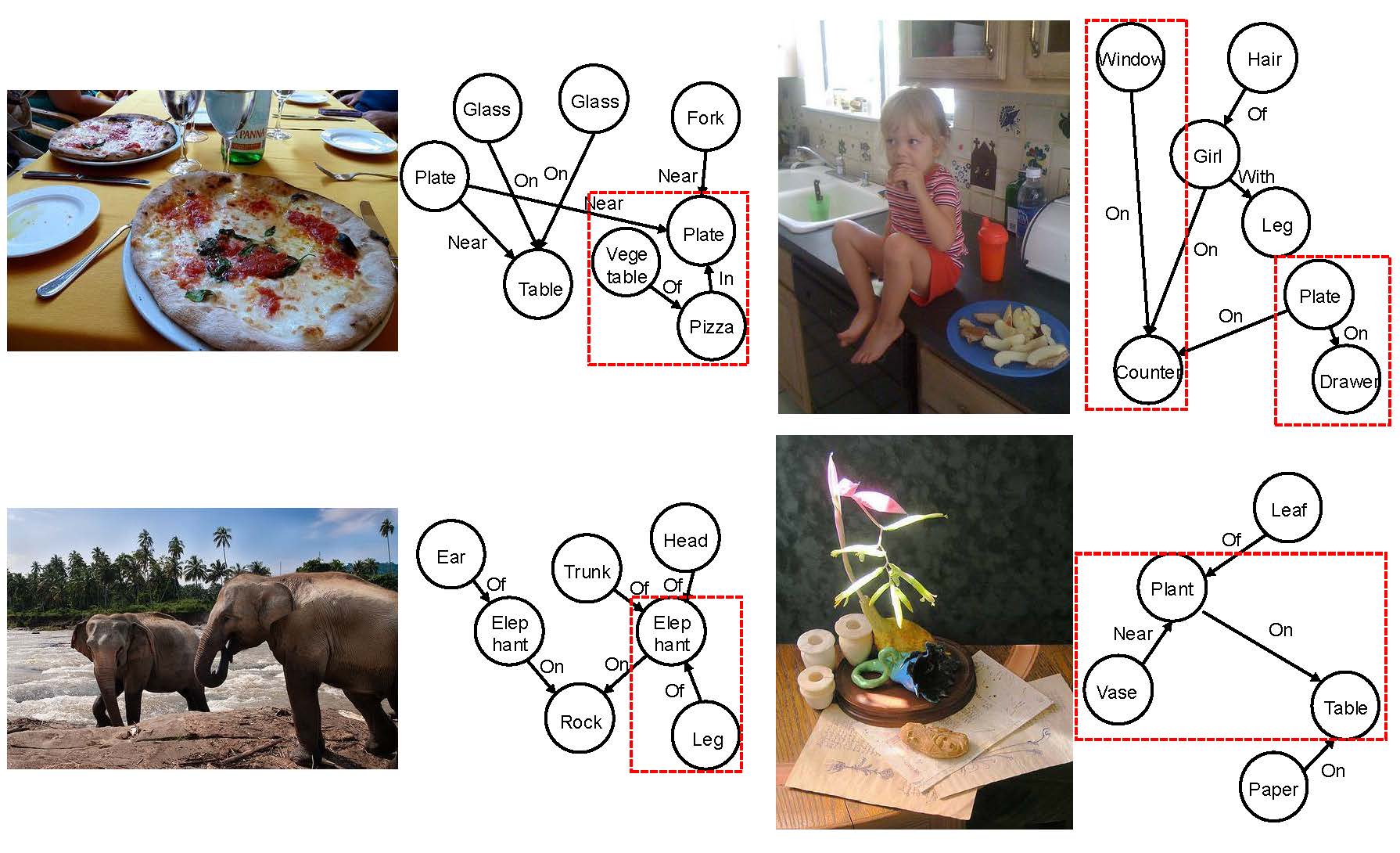
Scene graph generation is a pivotal task in computer vision, aiming to identify all visual relation tuples within an image. The advancement of methods involving triplets has sought to enhance task performance by integrating triplets as contextual features for more precise predicate identification from component level. However, challenges remain due to interference from multi-role objects in overlapping tuples within complex environments, which impairs the model's ability to distinguish and align specific triplet features for reasoning diverse semantics of multi-role objects. To address these issues, we introduce a novel framework that incorporates a triplet alignment model into a hybrid reciprocal transformer architecture, starting from using triplet mask features to guide the learning of component-level relation graphs. To effectively distinguish multi-role objects characterized by overlapping visual relation tuples, we introduce a triplet alignment loss, which provides multi-role objects with aligned features from triplet and helps customize them. Additionally, we explore the inherent connectivity between hybrid aligned triplet and component features through a bidirectional refinement module, which enhances feature interaction and reciprocal reinforcement. Experimental results demonstrate that our model achieves state-of-the-art performance on the Visual Genome and Action Genome datasets, underscoring its effectiveness and adaptability.

Coming Soon!
@inproceedings{fu2025hybrid,
title={Hybrid Reciprocal Transformer with Triplet Feature Alignment for Scene Graph Generation},
author={Fu, Jiawei and Zhang, Tiantian and Chen, Kai and Dou, Qi},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2025}
}